rickawsb
用戶暫無簡介
rickawsb
新紀錄!20萬人口規模城市級別的15年超長期電力合同將帶來哪些影響?
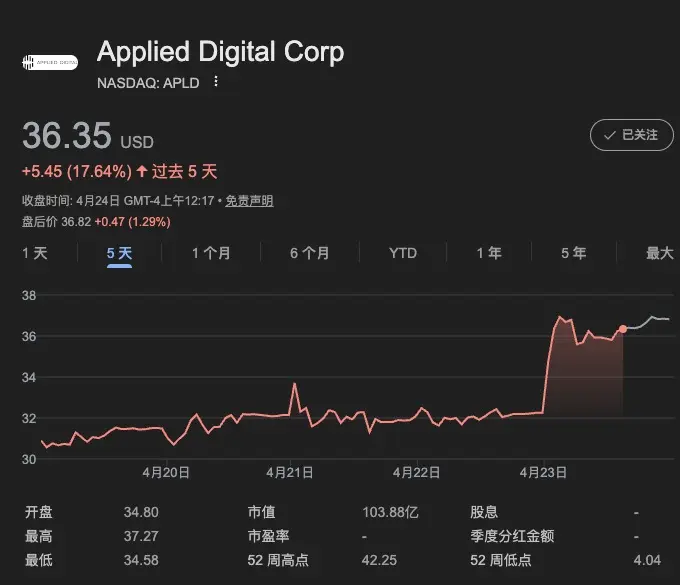
Applied Digital Corporation(apld) 今天宣布與一家美國投資級 hyperscaler 簽下一份 300MW、15年期、總額約75億美元的長約。
股價應聲大漲近20%。
300MW的規模已經接近20萬人口城市級負載,15年的期限明顯超出傳統數據中心合同;而按容量鎖定的模式,也不同於按GPU或按小時計費的算力租賃。
這在“超大規模 + 超長周期 + 明確算力用途”的基礎設施級AI合同上,創了新的紀錄。
這背後對應的是行業屬性的變化。截止目前的數據中心,本質上仍是IT服務,儘管之前有一些長達5年的合同,但擴容仍按需進行,資源可以遷移和替換;
而現在則逐步變成基礎設施資產,開始用類似電力PPA或能源的15年的長期合同的方式鎖定供給。
算力不再是可以隨時採購的資源,而是需要提前規劃、提前佔位的生產能力。
為什麼會發生這種變化,本質原因是資源開始稀缺,和儲存、芯片、光模塊一樣,對hyperscaler來說,如果不提前鎖定,未來可能根本拿不到資源。
在接下來的演進中,電力資產會被重新定價,甚至重新定義。
有電、有接入能力,和高達100–300MW甚至GW級別的電力擴展能力,同時具備網絡連接條件和開發可行性,都將成為新資產定價的屬性。
歸根結底,這一切指向同一個變化:AI競爭正在從模型和算法層,轉
查看原文Applied Digital Corporation(apld) 今天宣布與一家美國投資級 hyperscaler 簽下一份 300MW、15年期、總額約75億美元的長約。
股價應聲大漲近20%。
300MW的規模已經接近20萬人口城市級負載,15年的期限明顯超出傳統數據中心合同;而按容量鎖定的模式,也不同於按GPU或按小時計費的算力租賃。
這在“超大規模 + 超長周期 + 明確算力用途”的基礎設施級AI合同上,創了新的紀錄。
這背後對應的是行業屬性的變化。截止目前的數據中心,本質上仍是IT服務,儘管之前有一些長達5年的合同,但擴容仍按需進行,資源可以遷移和替換;
而現在則逐步變成基礎設施資產,開始用類似電力PPA或能源的15年的長期合同的方式鎖定供給。
算力不再是可以隨時採購的資源,而是需要提前規劃、提前佔位的生產能力。
為什麼會發生這種變化,本質原因是資源開始稀缺,和儲存、芯片、光模塊一樣,對hyperscaler來說,如果不提前鎖定,未來可能根本拿不到資源。
在接下來的演進中,電力資產會被重新定價,甚至重新定義。
有電、有接入能力,和高達100–300MW甚至GW級別的電力擴展能力,同時具備網絡連接條件和開發可行性,都將成為新資產定價的屬性。
歸根結底,這一切指向同一個變化:AI競爭正在從模型和算法層,轉
- 打賞
- 按讚
- 留言
- 轉發
- 分享
半導體封裝的“隱形中樞”:inline檢測與OSAT的再定價
半導體產業正在經歷一次重心轉移:性能提升不再只依賴晶體管縮小,而是越來越依賴封裝。2.5D、3D、HBM、chiplet,本質上都在把“系統能力”搬到封裝環節。這也直接提高了OSAT(外包封裝與測試)的戰略地位。
封裝重要性的提升,帶來了inline檢測的快速成長。
OSAT(Outsourced Semiconductor Assembly and Test)負責兩件事:
把裸die封裝成可用晶片(封裝)
驗證晶片是否可用(測試)
過去這是一个低技術、低毛利的環節。但在AI時代,情況變了:
多die集成(chiplet)
HBM堆疊
nm級對準要求(hybrid bonding)
封裝正在變成:
性能瓶頸 + 良率瓶頸 + 成本瓶頸
inline是一種生產方式:所有工序連續完成,並在生產過程中實時檢測與反饋(閉環)
對應另一個環節是offline:做完再測(開環)
先進封裝中的inline檢測主要分三類:
1)光學檢測(主力)
bump高度
overlay(對準)
表面缺陷
特點:速度快,可全量inline。
2)X-ray檢測
焊點空洞
TSV缺陷
內部結構問題
特點:能看內部,但速度慢,多用於抽檢。
3)電性測試
功能驗證
性能分檔
更接近最終測試,不屬於核心inline控制體系。
inline檢測的目標不是“最精
查看原文半導體產業正在經歷一次重心轉移:性能提升不再只依賴晶體管縮小,而是越來越依賴封裝。2.5D、3D、HBM、chiplet,本質上都在把“系統能力”搬到封裝環節。這也直接提高了OSAT(外包封裝與測試)的戰略地位。
封裝重要性的提升,帶來了inline檢測的快速成長。
OSAT(Outsourced Semiconductor Assembly and Test)負責兩件事:
把裸die封裝成可用晶片(封裝)
驗證晶片是否可用(測試)
過去這是一个低技術、低毛利的環節。但在AI時代,情況變了:
多die集成(chiplet)
HBM堆疊
nm級對準要求(hybrid bonding)
封裝正在變成:
性能瓶頸 + 良率瓶頸 + 成本瓶頸
inline是一種生產方式:所有工序連續完成,並在生產過程中實時檢測與反饋(閉環)
對應另一個環節是offline:做完再測(開環)
先進封裝中的inline檢測主要分三類:
1)光學檢測(主力)
bump高度
overlay(對準)
表面缺陷
特點:速度快,可全量inline。
2)X-ray檢測
焊點空洞
TSV缺陷
內部結構問題
特點:能看內部,但速度慢,多用於抽檢。
3)電性測試
功能驗證
性能分檔
更接近最終測試,不屬於核心inline控制體系。
inline檢測的目標不是“最精
- 打賞
- 1
- 1
- 轉發
- 分享
ybaser:
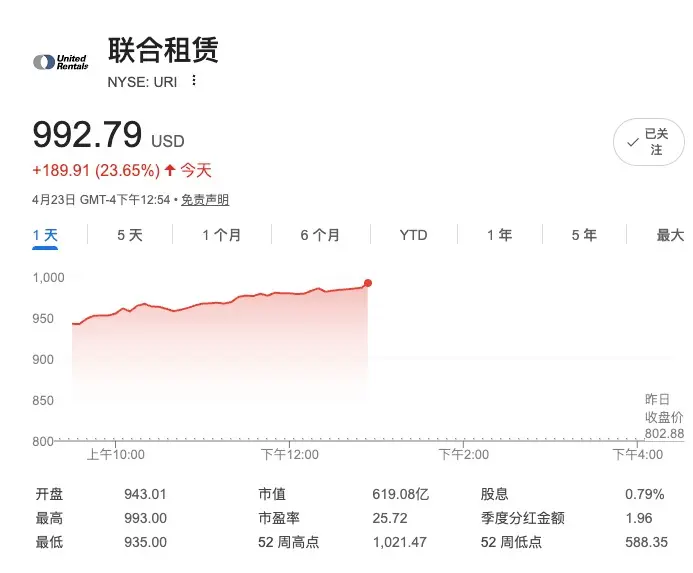
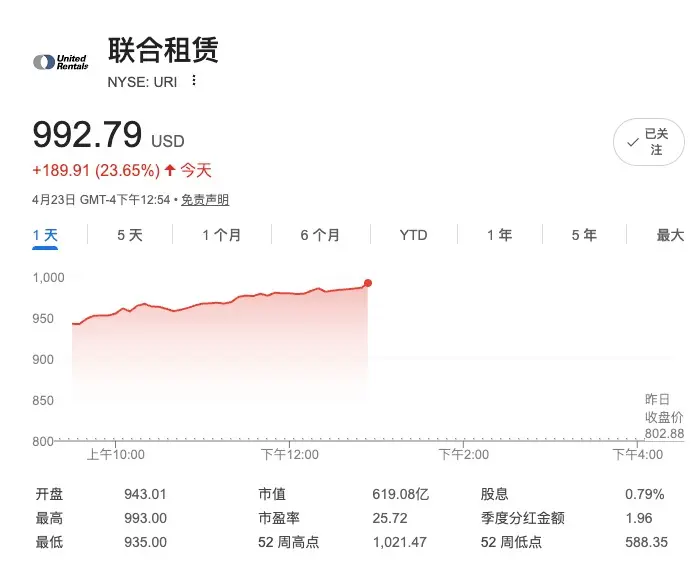
只需充電即可完成 👊United Rentals (URI),昨天財報,今天大漲超過20%!
這是在aidc瘋狂競逐算力的大周期裡,市場忽略的支撐這些龐然大物落地的“重型後勤”。
1. 業績摘要:創紀錄,上調指引
URI 在本季度交出了滿分答卷:
營收與盈利: 總營收 39.85 億美元,調整後每股盈餘達 $9.71。
核心效率: 租賃利潤率在排除特殊因素後持續走高,車隊生產力增長 2.3%。
股東回報: 季度內通過回購和派息返還 5 億美元,現金流極度充沛。最關鍵的信號是,管理層基於“大型項目勢頭”上調了全年業績指引,顯示出極強的增長信心。
2. 商業模式:從“租挖掘機”到“系統方案”
URI 的業務由兩部分驅動:
通用租賃: 覆蓋建築和工業的基礎設備(高空平台、土方機械等)。
專業租賃: 提供電力配套(大型發電機)、精密溫控(工業 HVAC)及流體處理。這種“一站式”模式讓它成為了大型工程不可替代的合作夥伴。
3. AIDC:URI 增長的“秘密燃料”
為什麼 AIDC 建設對 URI 如此重要?
重度依賴電力與溫控: AIDC 的建設和測試階段對移動電力和工業冷水機組有爆發式需求,這正是 URI 高毛利的專業租賃領域。
長周期與高粘性: 數據中心屬於“超大型項目(Mega Projects)”,建設周期長、設備佔用率高。
行業風向標: URI 約 25% 的收入來自這類大型項目。只要 AIDC
查看原文這是在aidc瘋狂競逐算力的大周期裡,市場忽略的支撐這些龐然大物落地的“重型後勤”。
1. 業績摘要:創紀錄,上調指引
URI 在本季度交出了滿分答卷:
營收與盈利: 總營收 39.85 億美元,調整後每股盈餘達 $9.71。
核心效率: 租賃利潤率在排除特殊因素後持續走高,車隊生產力增長 2.3%。
股東回報: 季度內通過回購和派息返還 5 億美元,現金流極度充沛。最關鍵的信號是,管理層基於“大型項目勢頭”上調了全年業績指引,顯示出極強的增長信心。
2. 商業模式:從“租挖掘機”到“系統方案”
URI 的業務由兩部分驅動:
通用租賃: 覆蓋建築和工業的基礎設備(高空平台、土方機械等)。
專業租賃: 提供電力配套(大型發電機)、精密溫控(工業 HVAC)及流體處理。這種“一站式”模式讓它成為了大型工程不可替代的合作夥伴。
3. AIDC:URI 增長的“秘密燃料”
為什麼 AIDC 建設對 URI 如此重要?
重度依賴電力與溫控: AIDC 的建設和測試階段對移動電力和工業冷水機組有爆發式需求,這正是 URI 高毛利的專業租賃領域。
長周期與高粘性: 數據中心屬於“超大型項目(Mega Projects)”,建設周期長、設備佔用率高。
行業風向標: URI 約 25% 的收入來自這類大型項目。只要 AIDC
- 打賞
- 按讚
- 留言
- 轉發
- 分享
United Rentals (URI),昨天財報,今天大漲超過20%!
這是在aidc瘋狂競逐算力的大周期裡,市場忽略的支撐這些龐然大物落地的“重型後勤”。
1. 業績摘要:創紀錄,上調指引
URI 在本季度交出了滿分答卷:
營收與盈利: 總營收 39.85 億美元,調整後每股盈餘達 $9.71。
核心效率: 租賃利潤率在排除特殊因素後持續走高,車隊生產力增長 2.3%。
股東回報: 季度內通過回購和派息返還 5 億美元,現金流極度充沛。最關鍵的信號是,管理層基於“大型項目勢頭”上調了全年業績指引,顯示出極強的增長信心。
2. 商業模式:從“租挖掘機”到“系統方案”
URI 的業務由兩部分驅動:
通用租賃: 覆蓋建築和工業的基礎設備(高空平台、土方機械等)。
專業租賃: 提供電力配套(大型發電機)、精密溫控(工業 HVAC)及流體處理。這種“一站式”模式讓它成為了大型工程不可替代的合作夥伴。
3. AIDC:URI 增長的“秘密燃料”
為什麼 AIDC 建設對 URI 如此重要?
重度依賴電力與溫控: AIDC 的建設和測試階段對移動電力和工業冷水機組有爆發式需求,這正是 URI 高毛利的專業租賃領域。
長周期與高粘性: 數據中心屬於“超大型項目(Mega Projects)”,建設周期長、設備佔用率高。
行業風向標: URI 約 25% 的收入來自這類大型項目。只要 AIDC
查看原文這是在aidc瘋狂競逐算力的大周期裡,市場忽略的支撐這些龐然大物落地的“重型後勤”。
1. 業績摘要:創紀錄,上調指引
URI 在本季度交出了滿分答卷:
營收與盈利: 總營收 39.85 億美元,調整後每股盈餘達 $9.71。
核心效率: 租賃利潤率在排除特殊因素後持續走高,車隊生產力增長 2.3%。
股東回報: 季度內通過回購和派息返還 5 億美元,現金流極度充沛。最關鍵的信號是,管理層基於“大型項目勢頭”上調了全年業績指引,顯示出極強的增長信心。
2. 商業模式:從“租挖掘機”到“系統方案”
URI 的業務由兩部分驅動:
通用租賃: 覆蓋建築和工業的基礎設備(高空平台、土方機械等)。
專業租賃: 提供電力配套(大型發電機)、精密溫控(工業 HVAC)及流體處理。這種“一站式”模式讓它成為了大型工程不可替代的合作夥伴。
3. AIDC:URI 增長的“秘密燃料”
為什麼 AIDC 建設對 URI 如此重要?
重度依賴電力與溫控: AIDC 的建設和測試階段對移動電力和工業冷水機組有爆發式需求,這正是 URI 高毛利的專業租賃領域。
長周期與高粘性: 數據中心屬於“超大型項目(Mega Projects)”,建設周期長、設備佔用率高。
行業風向標: URI 約 25% 的收入來自這類大型項目。只要 AIDC
- 打賞
- 1
- 1
- 轉發
- 分享
HighAmbition:
鑽石手 💎德州儀器($TXN)第一季度財報,全面超預期:
每股收益(EPS):1.68美元(預期1.38美元)
營收:48.3億美元(預期45.3億美元)
營業利潤:18.1億美元(預期15.4億美元)
自由現金流:14.0億美元(預期12.0億美元)
資本支出(CapEx):6.76億美元(預期6.899億美元)
模擬晶片收入:39.2億美元(預期36.8億美元)
業績指引(Q2):
預計每股收益(EPS):1.77–2.05美元
預計營收:50.0億–54.0億美元
連最關鍵的模擬業務也明顯好於市場此前的悲觀判斷。
財報釋放了三個更重要的信號。
第一,模擬晶片行業的庫存週期已經接近結束,整個板塊有被重新估值的基礎。
第二,工業需求比市場預期更強,全球製造並沒有想像中那麼疲弱。
第三,TXN在週期底部依然維持較強盈利能力,說明它不是簡單的週期公司,而是具備結構性優勢的長期贏家。
在這次AI週期中,需求傳導路徑是從算力延伸到電源、再到模擬和功率器件。
TXN正處在這條鏈條的中下游。當AI投資持續擴大時,這部分需求會逐步顯現出來,而且往往滯後但更穩定。
免責聲明:本人持有文章提及股票,觀點充滿偏見,非投資建議dyor
查看原文每股收益(EPS):1.68美元(預期1.38美元)
營收:48.3億美元(預期45.3億美元)
營業利潤:18.1億美元(預期15.4億美元)
自由現金流:14.0億美元(預期12.0億美元)
資本支出(CapEx):6.76億美元(預期6.899億美元)
模擬晶片收入:39.2億美元(預期36.8億美元)
業績指引(Q2):
預計每股收益(EPS):1.77–2.05美元
預計營收:50.0億–54.0億美元
連最關鍵的模擬業務也明顯好於市場此前的悲觀判斷。
財報釋放了三個更重要的信號。
第一,模擬晶片行業的庫存週期已經接近結束,整個板塊有被重新估值的基礎。
第二,工業需求比市場預期更強,全球製造並沒有想像中那麼疲弱。
第三,TXN在週期底部依然維持較強盈利能力,說明它不是簡單的週期公司,而是具備結構性優勢的長期贏家。
在這次AI週期中,需求傳導路徑是從算力延伸到電源、再到模擬和功率器件。
TXN正處在這條鏈條的中下游。當AI投資持續擴大時,這部分需求會逐步顯現出來,而且往往滯後但更穩定。
免責聲明:本人持有文章提及股票,觀點充滿偏見,非投資建議dyor
- 打賞
- 1
- 留言
- 轉發
- 分享
lam research财报前瞻
LRCX马上要发的财报的重点,其实是关于LRCX在AI周期里到底处在什么位置,以及它的变化会如何传导到整个产业链。
LRCX不是一个简单的设备公司,而是一个典型的工艺复杂度受益者。
AI带来的变化,并不只是算力需求增加,而是芯片制造过程本身的复杂度在快速上升:HBM堆叠层数提升、TSV深孔刻蚀难度提升、3D NAND层数逼近物理极限、2nm/GAA结构三维化。这些变化的共同结果,是单位晶圆需要的刻蚀和沉积步骤显著增加,且难度更高。
这意味着,LRCX的增长逻辑并不完全依赖“产能扩张”,而是更多来自“工艺密度提升”。
因此,财报是否超预期其实不是最关键的,关键是预期差来自哪里。影响财报结果的核心变量可以归纳为五个:预期是否已经被上调、订单是否顺利转化为收入、收入结构是否来自AI/先进封装、服务业务是否稳定、以及管理层指引是否保守。
但股价反应的逻辑未必和财报完全趋同。市场交易的不是结果,而是偏差。真正驱动股价的,是四件事:是否超出buy-side预期、指引是否上修、增长是否来自AI等高质量需求,以及毛利率是否稳定。在当前阶段,毛利率的重要性甚至高于收入,因为市场已经默认需求很强,但对“增长质量”更敏感。
因此,即便财报大概率超预期,股价也未必上涨。
就供给侧来说,LRCX未来并不会像ASML那样出现长期产能受限。刻蚀和沉积设备本身是可扩产的,公司也在
LRCX马上要发的财报的重点,其实是关于LRCX在AI周期里到底处在什么位置,以及它的变化会如何传导到整个产业链。
LRCX不是一个简单的设备公司,而是一个典型的工艺复杂度受益者。
AI带来的变化,并不只是算力需求增加,而是芯片制造过程本身的复杂度在快速上升:HBM堆叠层数提升、TSV深孔刻蚀难度提升、3D NAND层数逼近物理极限、2nm/GAA结构三维化。这些变化的共同结果,是单位晶圆需要的刻蚀和沉积步骤显著增加,且难度更高。
这意味着,LRCX的增长逻辑并不完全依赖“产能扩张”,而是更多来自“工艺密度提升”。
因此,财报是否超预期其实不是最关键的,关键是预期差来自哪里。影响财报结果的核心变量可以归纳为五个:预期是否已经被上调、订单是否顺利转化为收入、收入结构是否来自AI/先进封装、服务业务是否稳定、以及管理层指引是否保守。
但股价反应的逻辑未必和财报完全趋同。市场交易的不是结果,而是偏差。真正驱动股价的,是四件事:是否超出buy-side预期、指引是否上修、增长是否来自AI等高质量需求,以及毛利率是否稳定。在当前阶段,毛利率的重要性甚至高于收入,因为市场已经默认需求很强,但对“增长质量”更敏感。
因此,即便财报大概率超预期,股价也未必上涨。
就供给侧来说,LRCX未来并不会像ASML那样出现长期产能受限。刻蚀和沉积设备本身是可扩产的,公司也在

- 打賞
- 1
- 1
- 轉發
- 分享
HighAmbition:
多頭市場正處於巔峰 🐂凱文沃什國會聽證講話很鷹嗎?
“貨幣政策的獨立性至關重要。決策必須以國家利益為導向,建立在嚴謹分析、充分討論和清晰判斷之上。”
我覺得中規中矩啊,不然他还能怎麼說?
不表態維持聯儲獨立性,他能獲得國會通過嗎?
查看原文“貨幣政策的獨立性至關重要。決策必須以國家利益為導向,建立在嚴謹分析、充分討論和清晰判斷之上。”
我覺得中規中矩啊,不然他还能怎麼說?
不表態維持聯儲獨立性,他能獲得國會通過嗎?
- 打賞
- 按讚
- 留言
- 轉發
- 分享
訓練不足推理補
推理不足代理補
代理複雜約束補
約束麻煩大家補
所以,加速計算是智能,通用計算也是
在通往AGI的路上,存儲,GPU,CPU都會被榨乾,都會嚴重短缺
查看原文推理不足代理補
代理複雜約束補
約束麻煩大家補
所以,加速計算是智能,通用計算也是
在通往AGI的路上,存儲,GPU,CPU都會被榨乾,都會嚴重短缺
- 打賞
- 按讚
- 留言
- 轉發
- 分享
harness,我最喜歡的翻譯是
約束
所以harness engineer
應該叫做
約束工程
查看原文約束
所以harness engineer
應該叫做
約束工程
- 打賞
- 按讚
- 留言
- 轉發
- 分享
BWX Technologies 最近宣布收購 Precision Components Group,這是一次產能擴張,新增的50萬平方英尺廠房和400多名熟練工人,在核能需求重新啟動的周期裡,是能穩定交付的製造能力的保證。
核能正在進入一個新的上行周期。AI帶來的電力需求增長,叠加政策推動的小型模塊化反應堆(SMR)和能源結構轉型,使核能重新成為“穩定基荷電源”。
供需缺口急劇拉大。尤其是在美國,本土核工業製造能力長期萎縮,具備認證、工藝和經驗的生產體系極難複製。核級設備涉及嚴格的認證體系和極長的驗證周期,不是資本投入就能快速擴出的產能。
這使得行業的競爭邏輯發生變化。和之前的be邏輯類似,重要的是製造和按時交付。BWXT通過這次收購,把自身從“接單能力”進一步推向“交付能力”。
如果用類半導體產業鏈的視角去看,核能產業鏈也在逐漸出現類似“ASML / KLA”的角色。真正的核心在那些具備高認證、高複雜製造能力、且產能極難複製的供應層。
BWXT本身就是這一類公司,更接近“複雜度收費者”的角色。類似的還有 Curtiss-Wright,在泵、閥門和控制系統等關鍵部件上形成長期綁定,一旦進入供應鏈,生命周期可以鎖定幾十年。Chart Industries 則屬於跨能源體系的設備提供商,類似更廣義的“賣水人”。
相比之下,像 Westinghouse Electric Company
查看原文核能正在進入一個新的上行周期。AI帶來的電力需求增長,叠加政策推動的小型模塊化反應堆(SMR)和能源結構轉型,使核能重新成為“穩定基荷電源”。
供需缺口急劇拉大。尤其是在美國,本土核工業製造能力長期萎縮,具備認證、工藝和經驗的生產體系極難複製。核級設備涉及嚴格的認證體系和極長的驗證周期,不是資本投入就能快速擴出的產能。
這使得行業的競爭邏輯發生變化。和之前的be邏輯類似,重要的是製造和按時交付。BWXT通過這次收購,把自身從“接單能力”進一步推向“交付能力”。
如果用類半導體產業鏈的視角去看,核能產業鏈也在逐漸出現類似“ASML / KLA”的角色。真正的核心在那些具備高認證、高複雜製造能力、且產能極難複製的供應層。
BWXT本身就是這一類公司,更接近“複雜度收費者”的角色。類似的還有 Curtiss-Wright,在泵、閥門和控制系統等關鍵部件上形成長期綁定,一旦進入供應鏈,生命周期可以鎖定幾十年。Chart Industries 則屬於跨能源體系的設備提供商,類似更廣義的“賣水人”。
相比之下,像 Westinghouse Electric Company

- 打賞
- 按讚
- 留言
- 轉發
- 分享
我的claude opus 4.7了
大家應該都用上了?
查看原文大家應該都用上了?
- 打賞
- 按讚
- 留言
- 轉發
- 分享
模型即應用,算力即模型,剎那即永恆
—- Mythos發布觀感
經過過去幾年,從提示詞MCP、工作流skill到harness engineering的不斷迭代,市場應該已經基本認識到,
模型即應用。
接下來,隨著擁有足夠多算力的模型公司迭代速度越來越快,市場會慢慢意識到,
算力即模型,
隨著methos的發布,以及擁有算力優勢的頭部模型將領先優勢不斷拉大,讓一時的領先變成無法超越的加速度,最終,
剎那即永恆
查看原文—- Mythos發布觀感
經過過去幾年,從提示詞MCP、工作流skill到harness engineering的不斷迭代,市場應該已經基本認識到,
模型即應用。
接下來,隨著擁有足夠多算力的模型公司迭代速度越來越快,市場會慢慢意識到,
算力即模型,
隨著methos的發布,以及擁有算力優勢的頭部模型將領先優勢不斷拉大,讓一時的領先變成無法超越的加速度,最終,
剎那即永恆
- 打賞
- 2
- 留言
- 轉發
- 分享
模型即應用,算力即模型,剎那即永恆
—- mythos發布觀感
經過過去幾年,從提示詞MCP、工作流skill到harness engineering的不断迭代,市場應該已經基本認識到,
模型即應用。
接下來,隨著擁有多足算力的模型公司迭代速度越來越快,市場會慢慢意識到,
算力即模型,
隨著methos的發布,以及擁有算力優勢的頭部模型將領先優勢不斷拉大,讓一時的領先變成無法超越的加速度,最終,
剎那即永恆
查看原文—- mythos發布觀感
經過過去幾年,從提示詞MCP、工作流skill到harness engineering的不断迭代,市場應該已經基本認識到,
模型即應用。
接下來,隨著擁有多足算力的模型公司迭代速度越來越快,市場會慢慢意識到,
算力即模型,
隨著methos的發布,以及擁有算力優勢的頭部模型將領先優勢不斷拉大,讓一時的領先變成無法超越的加速度,最終,
剎那即永恆
- 打賞
- 1
- 留言
- 轉發
- 分享
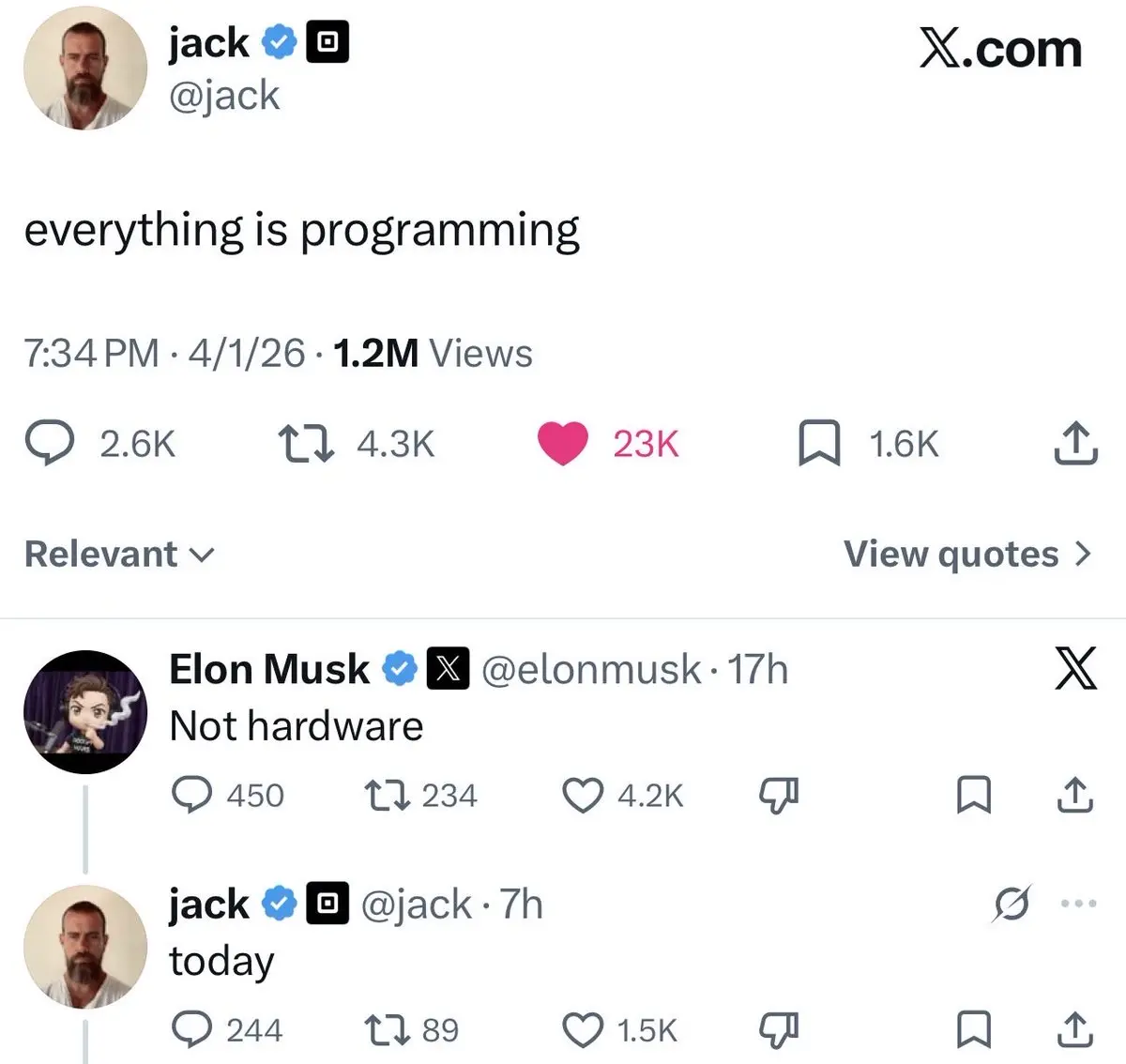
之前俄烏衝突就是民主黨負責點燃烏克蘭的戰火,製造混亂,然後川普負責撤軍,做撒手掌櫃,讓盟友買單。
這次伊朗估計時間太緊,川普把一套戲的兩個角色全演了,直接又負責點火製造混亂,又負責撒手不管,讓盟友買單。
查看原文這次伊朗估計時間太緊,川普把一套戲的兩個角色全演了,直接又負責點火製造混亂,又負責撒手不管,讓盟友買單。

- 打賞
- 1
- 留言
- 轉發
- 分享
伊朗局勢到現在,對於世界來說,這很可能只是混亂的開始,甚至不是開始的結束。
而對於美股這輪回調來說,這很可能就是已經是結束,至少是結束的開始
查看原文而對於美股這輪回調來說,這很可能就是已經是結束,至少是結束的開始
- 打賞
- 1
- 留言
- 轉發
- 分享
天弘、捷普、伟创力,過去一年多的業績都在大漲,裡面固然有AI大周期的拉動,但川普的關稅也功不可沒。如果不是關稅,現在的AI相關的EMS代工會在哪不用我說你應該也能猜得到
查看原文- 打賞
- 按讚
- 留言
- 轉發
- 分享
Qatar's Ras Laffan natural gas facility, which supplies approximately 20% of global LNG, was attacked. US LNG companies are about to laugh themselves awake.
The pricing logic of natural gas is changing. The US controls marginal supply—once Qatar has problems, the market naturally turns to the US.
The US and Greek LNG ship owners take away pricing power and liquidity premiums, while importing countries like Europe, Japan, and China bear the rising costs.
This issue isn't about energy shortage, but rather a shift in pricing power.
And the impact won't stop at energy itself, but will continue to
查看原文The pricing logic of natural gas is changing. The US controls marginal supply—once Qatar has problems, the market naturally turns to the US.
The US and Greek LNG ship owners take away pricing power and liquidity premiums, while importing countries like Europe, Japan, and China bear the rising costs.
This issue isn't about energy shortage, but rather a shift in pricing power.
And the impact won't stop at energy itself, but will continue to
- 打賞
- 按讚
- 留言
- 轉發
- 分享
十八大報告裡以經濟建設為中心,出現了四次,十九大出現了一次,
相反以人民為中心,十八大報告裡出現了一次,十九大出現了四次
我可以理解為,這是又要從搞錢,轉向搞人了嗎?😂
查看原文相反以人民為中心,十八大報告裡出現了一次,十九大出現了四次
我可以理解為,這是又要從搞錢,轉向搞人了嗎?😂
- 打賞
- 1
- 留言
- 轉發
- 分享
熱門話題
查看更多83.56萬 熱度
20.5萬 熱度
7.9萬 熱度
2.85萬 熱度
3.08萬 熱度
置頂
🔥 WCTC S8 全球交易賽正式開賽!
8,000,000 USDT 超級獎池解鎖開啟
🏆 團隊賽:上半場正式開啟,預報名階段 5,500+ 戰隊現已集結
交易量收益額雙重比拼,解鎖上半場 1,800,000 USDT 獎池
🏆 個人賽:現貨、合約、TradFi、ETF、閃兌、跟單齊上陣
全場交易量比拼,瓜分 2,000,000 USDT 獎池
🏆 王者 PK 賽:零門檻參與,實時匹配享受戰鬥快感
收益率即時 PK,瓜分 1,600,000 USDT 獎池
活動時間:2026 年 4 月 23 日 16:00:00 - 2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即參與:https://www.gate.com/competition/wctc-s8
#WCTCS810,000 USDT 悬賞,尋找跟單金牌星探!🕵️
挖掘頂級帶單員,贏取高額跟單體驗金!
立即參與:https://www.gate.com/campaigns/4624
🎁 三大活動,獎金疊滿:
1️⃣ 慧眼識英:發帖推薦帶單員,分享跟單體驗,抽 100 位送 30 USDT!
2️⃣ 強力應援:曬出你的跟單截圖,為大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交達人:同步至 X/Twitter,憑流量贏取 100 USDT!
📍 標籤: #跟单金牌星探 #GateCopyTrading
⏰ 限時: 4/22 16:00 - 5/10 16:00 (UTC+8)
詳情:https://www.gate.com/announcements/article/50848十三載風雨同行,您是 Gate 最珍貴的見證者。分享您的故事,瓜分重磅週年豪禮!
參與方式
1️⃣ 帶 #Gate13周年 和相應主題標籤,在 13 周年留言板或廣場發帖
2️⃣ 分享您與 Gate 的故事、送上祝福,或暢想未來 13 年
13 周年定制禮盒、紅牛模型、大額倉位體驗券等您來拿!
13周年慶留言板 👉️ https://www.gate.com/activities/13th-anniversary
Gate 廣場 👉️ https://www.gate.com/post
13 年成長,感謝有您。您的故事,我們期待聆聽!
詳情:https://www.gate.com/announcements/article/50694✍️ Gate 廣場「創作者認證激勵計劃」進行中!
我們歡迎優質創作者積極創作,申請認證
贏取豪華代幣獎池、Gate 精美周邊、流量曝光等超過 $10,000+ 豐厚獎勵!
立即報名 👉 https://www.gate.com/questionnaire/7159
📕 認證申請步驟:
1️⃣ App 首頁底部進入【廣場】 → 點擊右上角頭像進入個人主頁
2️⃣ 點擊頭像右下角【申請認證】進入認證頁面,等待審核
讓優質內容被更多人看到,一起共建創作者社區!
活動詳情:https://www.gate.com/announcements/article/47889