
- 打賞
- 按讚
- 留言
- 轉發
- 分享
阿偉DOGE簡帖:
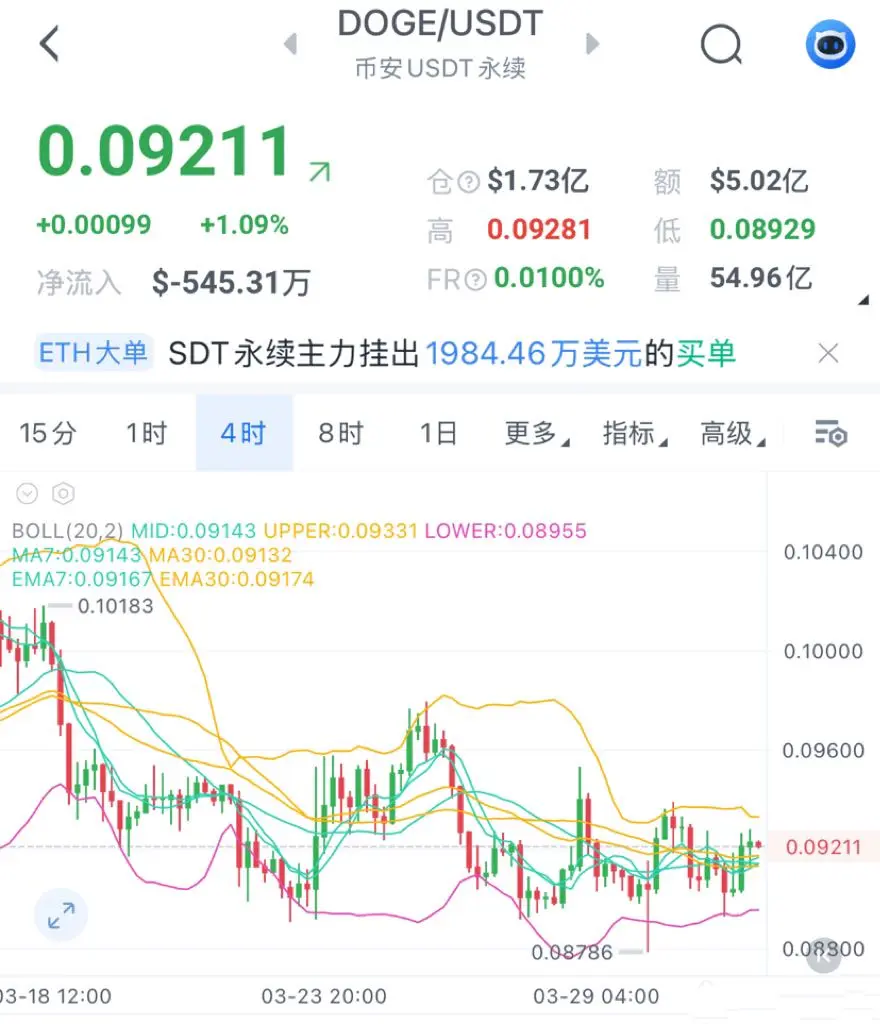
做空點位:0.09215-0.09325區間進場
目標點位:0.09103,0.08988
策略有實效性,行情說變就變,實盤得跟著盤面靈活調。帶好止損!$DOGE #鲍威尔鸽派发言重燃降息预期 #Gate金手指 #特朗普释放停战信号
做空點位:0.09215-0.09325區間進場
目標點位:0.09103,0.08988
策略有實效性,行情說變就變,實盤得跟著盤面靈活調。帶好止損!$DOGE #鲍威尔鸽派发言重燃降息预期 #Gate金手指 #特朗普释放停战信号
DOGE0.92%
- 打賞
- 按讚
- 留言
- 轉發
- 分享
JLM
脊梁米
創建人@GateUser-d76cc819
上市進度
100.00%
市值:
$1583.19
更多代幣
CT兄弟們是愚人節免疫的,他們有太多的信任問題
不要相信任何人,就像平常一樣
查看原文不要相信任何人,就像平常一樣

- 打賞
- 按讚
- 留言
- 轉發
- 分享
一直在玩 @spaace_io NFT 創作,說實話,最難的從來不是點子,而是圍繞它的一切。你需要設計師、時間、協調,等到你準備好推出時,通常已經失去了動力。
這也是為什麼 Flip 感覺是一個非常不同的方向。它不再將系列視為一次性項目,而是將其變成幾乎可以瞬間啟動的東西。你可以在幾分鐘內,從點子到完整的系列,包含特徵、稀有度和可用的元數據,而不是幾週。
更有趣的是,這如何融入更大的轉變。現在不僅僅是人類在創作。代理可以生成系列、測試變體、發布並持續迭代。這種速度改變了整個市場的運作方式。
你不再等待“重大釋出”。你可以不斷進行實驗。大多數可能沒什麼用,但這正是重點。當創作變得容易,發現就成了遊戲。
感覺 NFT 正在從緩慢、策劃的發布,轉向更流動、更有生命力的形式。而 Flip 可能是這一轉變最明顯的跡象之一。
這也是為什麼 Flip 感覺是一個非常不同的方向。它不再將系列視為一次性項目,而是將其變成幾乎可以瞬間啟動的東西。你可以在幾分鐘內,從點子到完整的系列,包含特徵、稀有度和可用的元數據,而不是幾週。
更有趣的是,這如何融入更大的轉變。現在不僅僅是人類在創作。代理可以生成系列、測試變體、發布並持續迭代。這種速度改變了整個市場的運作方式。
你不再等待“重大釋出”。你可以不斷進行實驗。大多數可能沒什麼用,但這正是重點。當創作變得容易,發現就成了遊戲。
感覺 NFT 正在從緩慢、策劃的發布,轉向更流動、更有生命力的形式。而 Flip 可能是這一轉變最明顯的跡象之一。
FLIP0.45%

- 打賞
- 按讚
- 留言
- 轉發
- 分享
每天在InterLink Network積極互動,你的每一步都在為未來加碼💜 成為Human Node,開始Mining,一起共建AI時代的人類網絡!堅持就是勝利~快通過下面專屬鏈接加入吧!
#InterLink #ITLG #ITL #InterLinkNetwork
查看原文#InterLink #ITLG #ITL #InterLinkNetwork

- 打賞
- 按讚
- 留言
- 轉發
- 分享
交易是指在短期內買賣金融資產(例如股票、加密貨幣、外匯/外匯或商品),以從市場價格波動中獲取利潤。與傾向於長期持有資產的投資不同,交易者每天密切關注市場,並做出快速決策——可能在幾分鐘、幾小時或幾天內——以利用價格的上升或下降波動。
查看原文
- 打賞
- 2
- 留言
- 轉發
- 分享
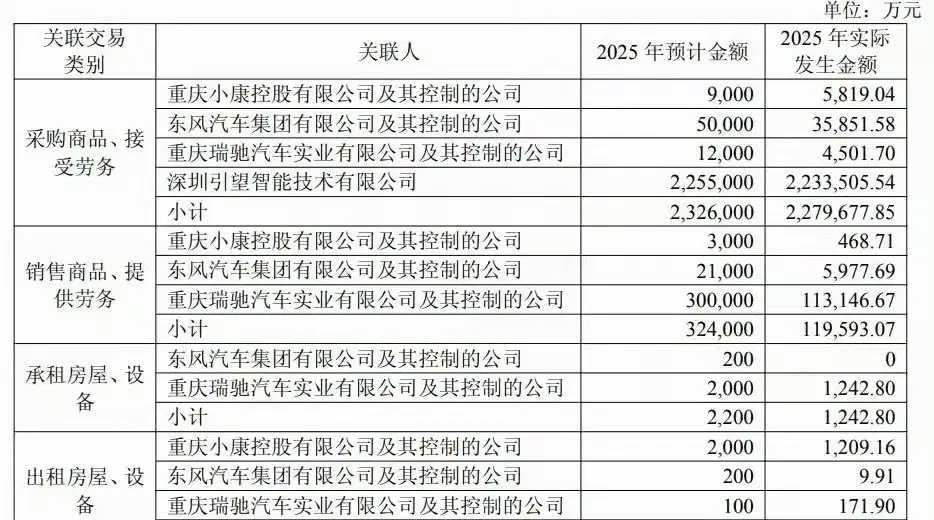
華為的車企品牌,賽力斯最近財報出爐
賽力斯2025年報:營收1650.5億,
其他數據:毛利443億,28.8%,淨利59.6億,約3%
研發125.1億元,問界交付超過42萬輛
銷售費用241.9億元,意味著每賣出一台車,花費超過5萬元的銷售和行銷費用
上次晚點報導,賽力斯賣一輛車平均需要向華為交14萬
假設一輛40萬的車,交14萬給華為,成本為26萬
在扣除28%的利潤(7.8萬)和5萬的行銷費用後
平均一輛問界的製造成本為13.2萬
不過13.2萬並不代表原材料費用,可能人工費用還要3萬,也就是說問界一台車的原材料應該不到10萬
查看原文賽力斯2025年報:營收1650.5億,
其他數據:毛利443億,28.8%,淨利59.6億,約3%
研發125.1億元,問界交付超過42萬輛
銷售費用241.9億元,意味著每賣出一台車,花費超過5萬元的銷售和行銷費用
上次晚點報導,賽力斯賣一輛車平均需要向華為交14萬
假設一輛40萬的車,交14萬給華為,成本為26萬
在扣除28%的利潤(7.8萬)和5萬的行銷費用後
平均一輛問界的製造成本為13.2萬
不過13.2萬並不代表原材料費用,可能人工費用還要3萬,也就是說問界一台車的原材料應該不到10萬
- 打賞
- 5
- 留言
- 轉發
- 分享


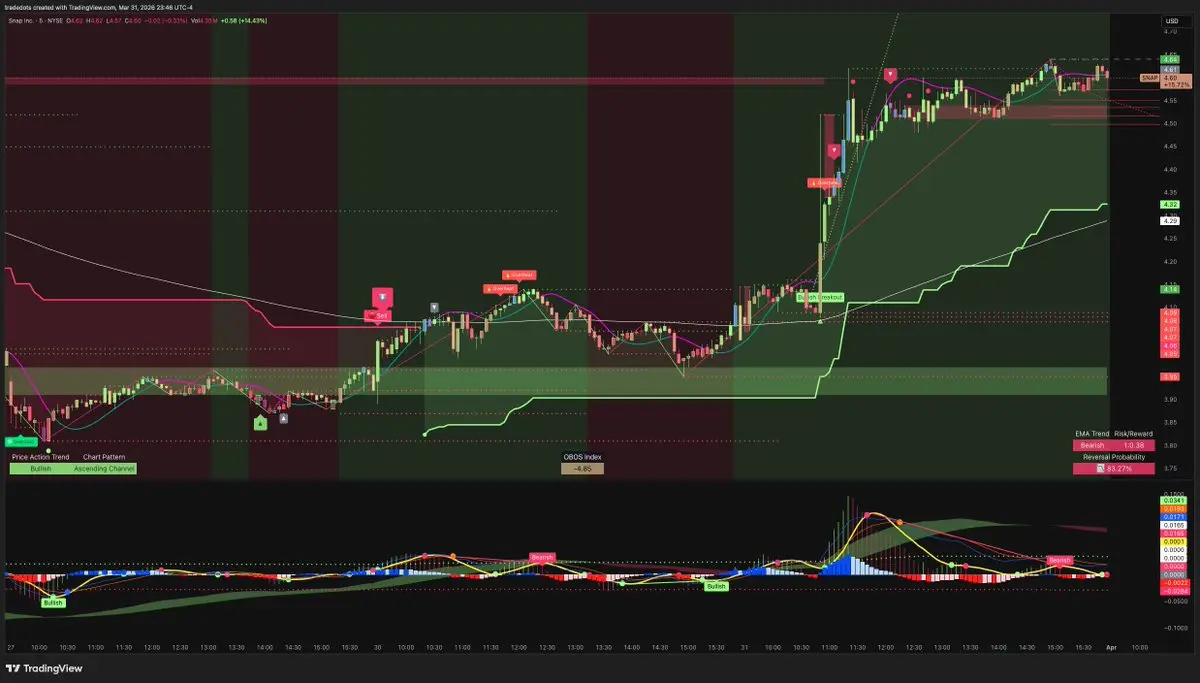
$SNAP:活動家信函概述價值解鎖計劃
情緒:正面
活動家 Irenic (經濟利益 ~2.5% 的A類股) 發布了一份計劃和信函給執行長 Evan Spiegel,主張 Snap 的價值可能達到每股 26.37 美元,推動有關貨幣化、訂閱和資產價值的重新討論,這些都能推動短期的頭條動能和戰略壓力。 (情緒分數:0.426)
查看原文情緒:正面
活動家 Irenic (經濟利益 ~2.5% 的A類股) 發布了一份計劃和信函給執行長 Evan Spiegel,主張 Snap 的價值可能達到每股 26.37 美元,推動有關貨幣化、訂閱和資產價值的重新討論,這些都能推動短期的頭條動能和戰略壓力。 (情緒分數:0.426)
- 打賞
- 1
- 留言
- 轉發
- 分享

- 打賞
- 2
- 留言
- 轉發
- 分享
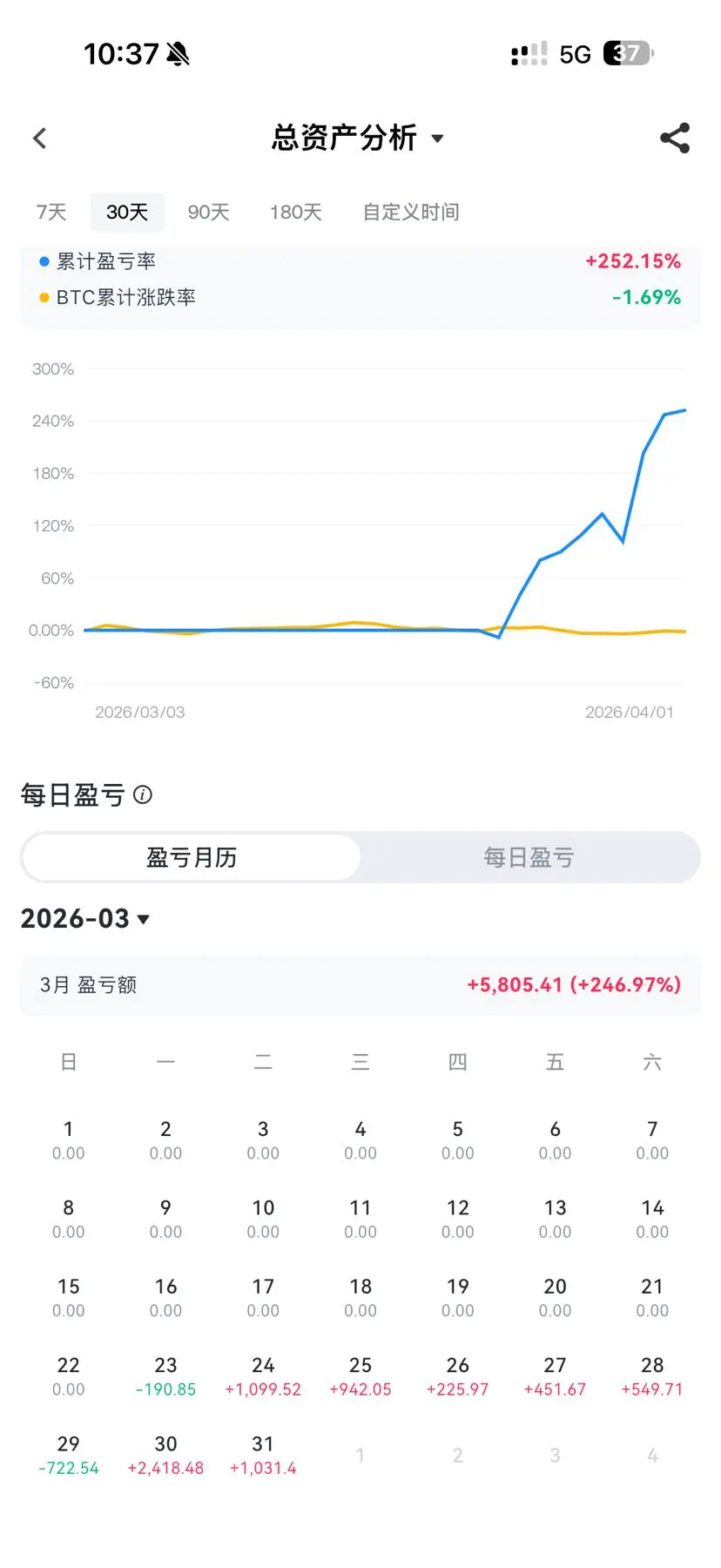
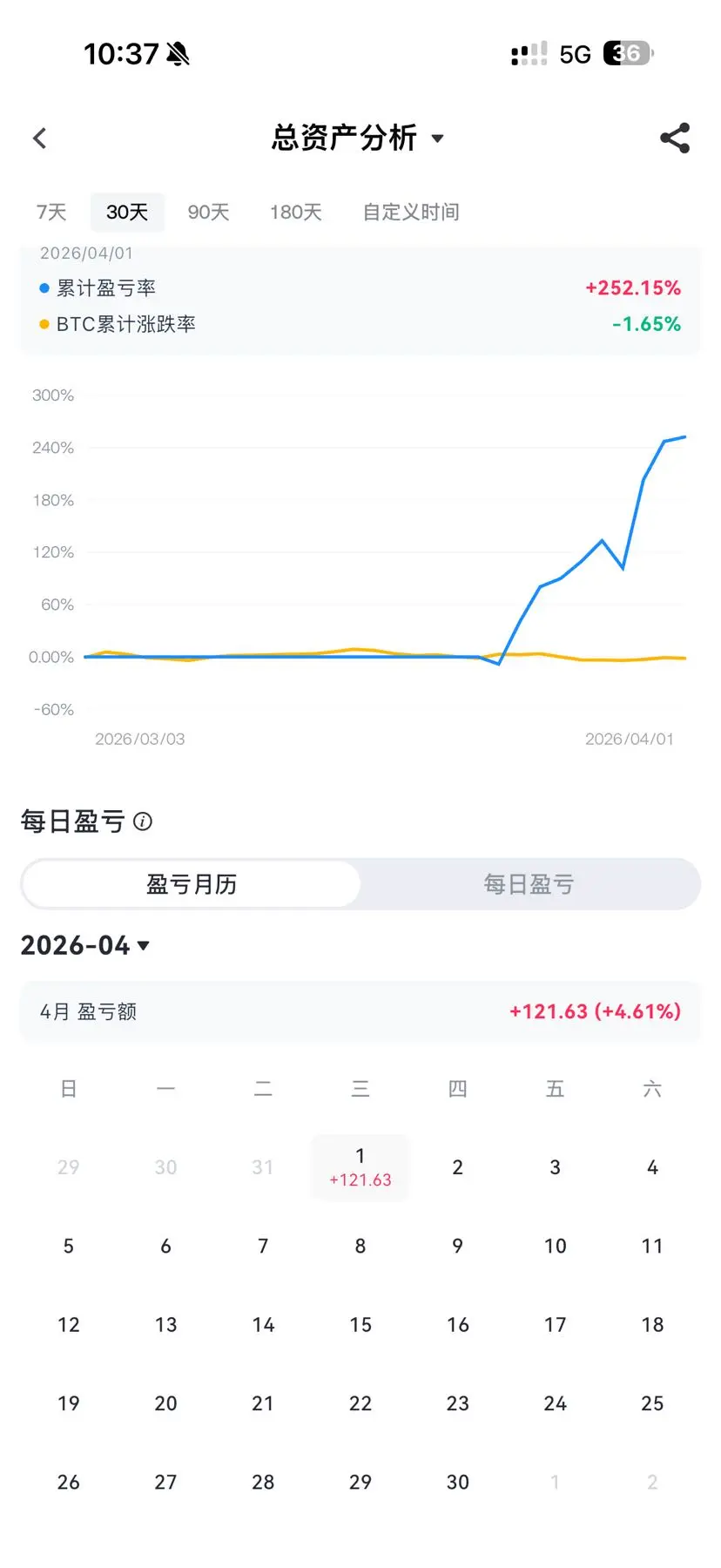


特斯马
TSM
創建人@北暖
上市進度
100.00%
市值:
$6519.35
更多代幣
3.31大盤晚間分析
大盤沖高68405美元後快速回落,布林帶開口向下拐頭,價格有效跌破中軌67033.9支撐,目前下探至下軌65987附近,反彈力度極弱,承壓中軌形成“陰跌”格局,短期均線呈空頭排列,空頭趨勢明確。
宏觀面更是雪上加霜:3月美元指數強勢走高,本月漲幅超過2.4%,美聯儲降息預期徹底逆轉,6月維持利率不變的概率達到92.5%,高利率環境持續抽走風險資產的流動性;再加上中東衝突推升油價至105美元的高位,通脹壓力倒逼政策收緊,資金從加密市場轉向美元與避險資產大黃,進一步壓制大盤估值。
此外,ETF連續淨流出、市場情緒處於極度恐懼區間,槓桿資金仍在出清。短期內大盤難以出現強勢反彈,大概率將延續震盪偏弱的格局,若66000點的支撐跌破,將打開60000-56000點的下行空間,操作上建議逢高做空,嚴格控制風險。
操作建議:反彈至67500-68000點區間,目標位65500-66000點。
查看原文大盤沖高68405美元後快速回落,布林帶開口向下拐頭,價格有效跌破中軌67033.9支撐,目前下探至下軌65987附近,反彈力度極弱,承壓中軌形成“陰跌”格局,短期均線呈空頭排列,空頭趨勢明確。
宏觀面更是雪上加霜:3月美元指數強勢走高,本月漲幅超過2.4%,美聯儲降息預期徹底逆轉,6月維持利率不變的概率達到92.5%,高利率環境持續抽走風險資產的流動性;再加上中東衝突推升油價至105美元的高位,通脹壓力倒逼政策收緊,資金從加密市場轉向美元與避險資產大黃,進一步壓制大盤估值。
此外,ETF連續淨流出、市場情緒處於極度恐懼區間,槓桿資金仍在出清。短期內大盤難以出現強勢反彈,大概率將延續震盪偏弱的格局,若66000點的支撐跌破,將打開60000-56000點的下行空間,操作上建議逢高做空,嚴格控制風險。
操作建議:反彈至67500-68000點區間,目標位65500-66000點。

- 打賞
- 2
- 留言
- 轉發
- 分享
新主播看以太坊
297
- 打賞
- 按讚
- 留言
- 轉發
- 分享
這一刻我知道了
孩子的陪伴>加密
你給他香港的房子遠遠不如陪伴
前段時間還打老婆了一頓
因為喊我看孩子
我在開單,老婆沒跑
加密影響你們生活嗎兄弟們
昨天晚上沒波動加上今天有事
晚上沒在大群喊單子
帶孩子去醫院周歲體檢了
醫生說落後同齡人了
每天爸爸必須和互動2小時
查看原文孩子的陪伴>加密
你給他香港的房子遠遠不如陪伴
前段時間還打老婆了一頓
因為喊我看孩子
我在開單,老婆沒跑
加密影響你們生活嗎兄弟們
昨天晚上沒波動加上今天有事
晚上沒在大群喊單子
帶孩子去醫院周歲體檢了
醫生說落後同齡人了
每天爸爸必須和互動2小時

- 打賞
- 按讚
- 留言
- 轉發
- 分享
#ClaudeCode500KCodeLeak 這個標籤最近在科技和開發者社群中引發了激烈討論,提出了關於人工智慧安全、智慧財產權以及大型語言模型未來的嚴肅問題。報導指出,一個包含約50萬行與先進AI系統相關的程式碼的龐大資料集已經被泄露到線上。儘管完整細節仍在揭示中,但其影響已經引發廣泛辯論。
這一事件的核心是對AI模型在程式設計、自動化和軟體開發中日益增長的依賴。由先進AI驅動的平台現在能夠生成複雜的程式碼、協助開發者,甚至建立整個應用程式。然而,這種能力也帶來了關鍵責任:保護支撐這些能力的底層資料和模型。
如果這次泄露屬實,可能不僅會曝光原始程式碼,還可能揭示現代AI系統設計的架構見解。這或許會讓競爭對手、駭客或惡意行為者得以研究並複製專有系統。更令人擔憂的是,程式碼中的漏洞可能被識別並利用,危及用戶和平台的安全。
對開發者而言,這次事件是一個警示。許多人每天依賴AI工具,信任他們的互動和生成的輸出是安全的。如此規模的泄露挑戰了這種信任,也凸顯了透明度和強健的網路安全實踐的重要性。開發者現在可能會對與AI系統分享的內容變得更加謹慎,尤其是在處理敏感或專有項目時。
從更廣泛的角度來看,這次爭議也涉及倫理層面。誰擁有AI生成或AI訓練的程式碼?企業應如何在保護模型的同時促進創新?當此類事件發生時,組織又有何責任?隨著AI逐步融入科技的每個層面,這些問題變得越來越重要。
另一方面,
查看原文這一事件的核心是對AI模型在程式設計、自動化和軟體開發中日益增長的依賴。由先進AI驅動的平台現在能夠生成複雜的程式碼、協助開發者,甚至建立整個應用程式。然而,這種能力也帶來了關鍵責任:保護支撐這些能力的底層資料和模型。
如果這次泄露屬實,可能不僅會曝光原始程式碼,還可能揭示現代AI系統設計的架構見解。這或許會讓競爭對手、駭客或惡意行為者得以研究並複製專有系統。更令人擔憂的是,程式碼中的漏洞可能被識別並利用,危及用戶和平台的安全。
對開發者而言,這次事件是一個警示。許多人每天依賴AI工具,信任他們的互動和生成的輸出是安全的。如此規模的泄露挑戰了這種信任,也凸顯了透明度和強健的網路安全實踐的重要性。開發者現在可能會對與AI系統分享的內容變得更加謹慎,尤其是在處理敏感或專有項目時。
從更廣泛的角度來看,這次爭議也涉及倫理層面。誰擁有AI生成或AI訓練的程式碼?企業應如何在保護模型的同時促進創新?當此類事件發生時,組織又有何責任?隨著AI逐步融入科技的每個層面,這些問題變得越來越重要。
另一方面,


- 打賞
- 1
- 1
- 轉發
- 分享
HighAmbition :
:
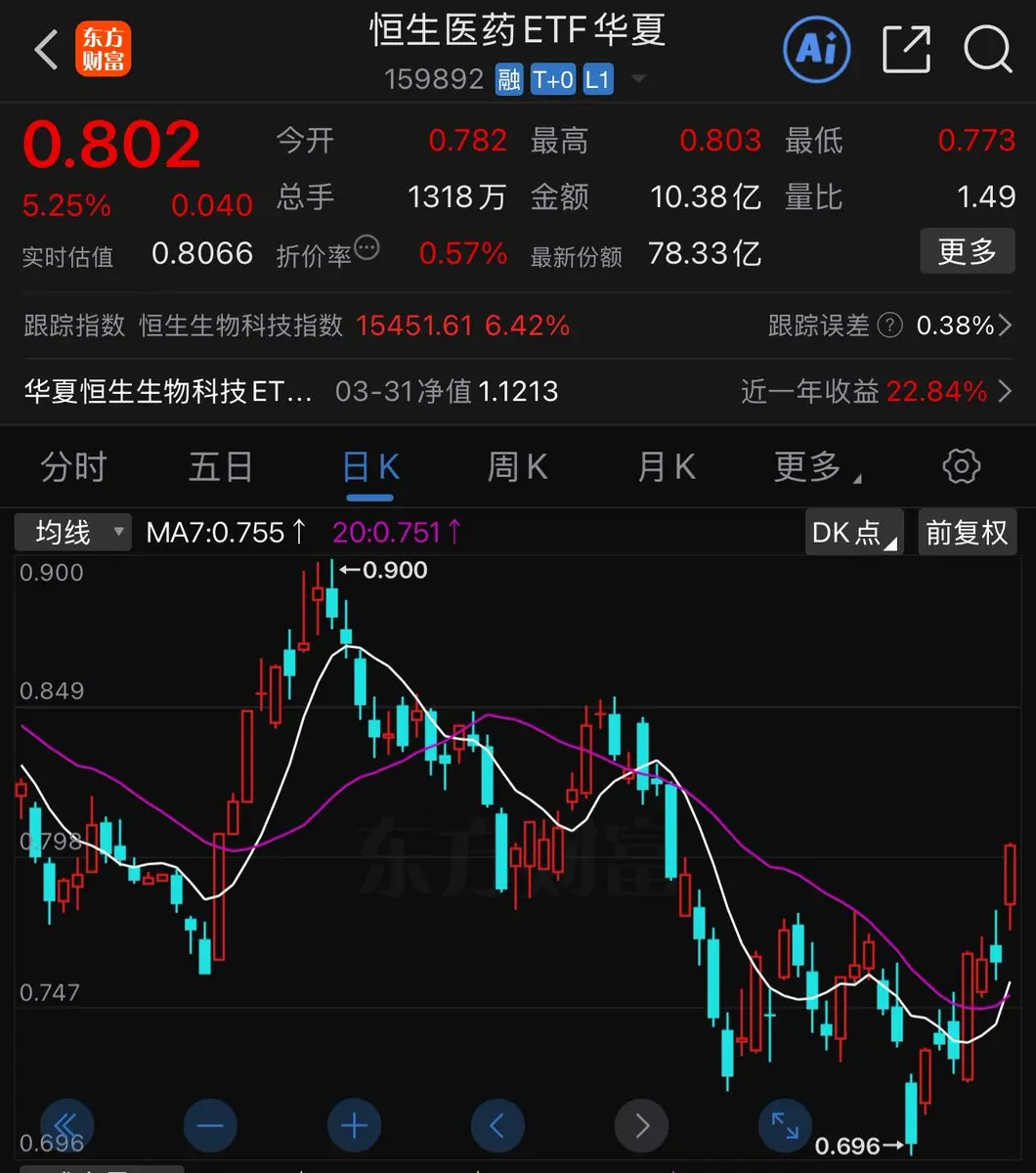
關於加密貨幣市場的好資訊BTC 4 月開門紅 68000 站穩了嗎?愚人節還是變盤日?
74
- 打賞
- 按讚
- 留言
- 轉發
- 分享
加載更多